Transformer概述
Transformer
Transformer是近些年一个比较火的机器学习模型,诞生于Google的机器翻译团队,原始论文为《Attention is All You Need》
什么是Transformer
Transformer其实从名字上可以看出来,该模型脱胎自一个翻译(Translate)应用,原始论文的标题其实也可以告诉我们,Transformer主要是依靠Attention机制。Transformer由于是NLP领域的模型,其主要是处理类似句子这种在前后维度(也就是两个词或多个词)上具有相关性的数据,也就是回归问题。但是由于其采用的Attention机制可以大大拓宽感受野,近来也在分类问题上能有一定的成就(例如CV领域,情感分析领域)。
Transformer怎么构成
对于Transformer本身的结构,甚至可以说比之前很多的NLP领域的模型要简洁易用的多,主要是由Encoder和Decoder两部分组成(如下图)
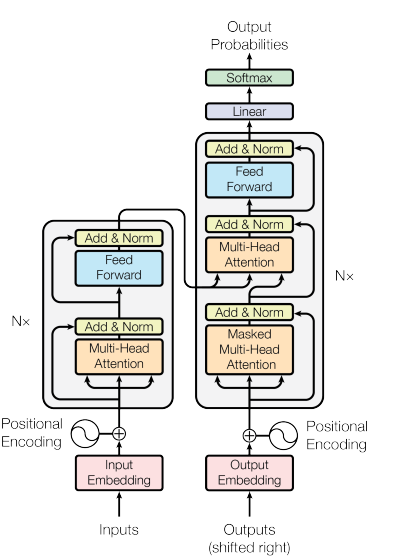
Transformer的优势
Transformer的机制
Transformer的应用代码
由于个人平时写pytorch,所以这里大部分代码都是基于pytorch的Python代码。
基于Transformer在时序预测领域的使用
模型的jupyter文件链接:https://colab.research.google.com/drive/1yG01IFE8tJU_E59iqEL0t2iFRyLaaTYA?usp=sharing
这个模型虽然不是标准的Transformer,但是采用了ConvTrans的模型,整体上是在Transformer的位置编码的时候增加了一个卷积层,具体实现我们将会在后面的博客讲解。
我这里实现的是利用Transformer将一段时间内(30天)的中国大陆几个城市(深圳,上海,北京,长春)的疫情数据进行预测,训练30天的数据,测试集为30-42天的疫情数据,输入12天的疫情数据,输出第13天的疫情数据,从而进行训练,并以此进行简单迁移,从而观测是否因此可以判断一个城市的防疫政策的好坏。由于数据量不足以及单纯进行简单迁移,同时考虑的维度过于简单,只能作为一个小的预测实验,效果一般。

